
結果を分析してみる
- 解説
- 1. 準備
- 2. サイコロを振る
- 3. 平均値
- 4. 中央値
- 5. 最頻値
解説
1. 準備
サイコロを好きな回数振れるようになったので、その結果を分析してみましょう。まずは純粋なPythonだけで基本的な統計値を算出してみます。次のページでライブラリを使用してもっと簡単に算出できるようになりますので、方法を覚える必要は無く、計算内容を把握するだけで構いません。
| (1) | Colab上で「step03.ipynb」を新規作成してください。 |
| (2) | 下記のコードをそれぞれ別々のセル入力してください。 |
# インポート
import random
# 定数
DICE_A = 'サイコロA'
DICE_B = 'サイコロB'
DICE_A_MAX = 6
DICE_B_MAX = 6
ROLLS = 10# 「サイコロを振る」のと同じ状態を再現する関数
# 引数1つ目はint型、dice_max=サイコロの最大値
# 引数2つ目はint型、dice_min=サイコロの最小値、省略時は1
# 戻り値はint型、サイコロを振った結果の目の値
def roll_dice(dice_max: int, dice_min: int = 1) -> int:
return random.randint(dice_min, dice_max)特に実行結果はありません。
2. サイコロを振る
Pythonでは同じ処理をいろいろな書き方で実現できます。ここでは、サイコロを振る処理を前回よりも短く書いてみましょう。
| (1) | 下記のコードを新しいセルに入力して、 「ランタイム」 > 「すべてのセルを実行」してください。 |
# リスト内包表記でサイコロをROLLS回振る
diceA_faces = [roll_dice(DICE_A_MAX) for _ in range(ROLLS)]
diceB_faces = [roll_dice(DICE_B_MAX) for _ in range(ROLLS)]
print('{}を{}回振った結果は{}でした'.format(DICE_A, ROLLS, diceA_faces))
print('{}を{}回振った結果は{}でした'.format(DICE_B, ROLLS, diceB_faces))実行して次のような結果が出力されればOKです。
サイコロAを10回振った結果は[3, 2, 3, 6, 3, 2, 6, 6, 2, 5]でした
サイコロBを10回振った結果は[1, 2, 3, 2, 5, 4, 5, 1, 5, 1]でしたポイント
リスト内包表記
前回は以下のような作りでしたね。
dice_faces = []
for count in range(ROLLS):
dice_face = roll_dice(DICE_MAX)
dice_faces.append(dice_face)今回はリスト内包表記という方法で1行で同等の処理を実現しています。
dice_faces = [roll_dice(DICE_MAX) for _ in range(ROLLS)]for _ in range(ROLLS) の部分は同じ感じですが、rangeによって作られた配列の中身には興味が無く、配列の長さ=繰り返す回数だけが重要なため、forとinの間の変数は「使わないよ」という意味を込めて「_(アンダーバー)」にしています。また、最後の「:(コロン)」もありません。
forの左には roll_dice(DICE_MAX) という関数の呼び出しだけが書いてあります。つまり、関数を呼び出した戻り値だけがforの左にある、という状態になります。
そしてこの全体を「[](角括弧)」で括っています。これで、「繰り返し生成した値を配列にする」というリスト内包表記のできあがりです。
もしまだイメージが追いつかなければ、次のコードを実行してみてください。
print([item for item in [1,3,5]])
print([item for item in range(4)])
print(['文字:' + item for item in ['a','b','c']])
print(['あ' for _ in [1,3,5]])
# 出力結果
[1, 3, 5]
[0, 1, 2, 3]
['文字:a', '文字:b', '文字:c']
['あ', 'あ', 'あ']3. 平均値
最初は平均値を算出してみます。平均値とは、すべての値を合計して、その結果を値の個数で割り算した結果です。
| (1) | 下記のコードを新しいセルに入力して、 「ランタイム」 > 「すべてのセルを実行」してください。 |
# サイコロをROLLS回振った結果の平均値を算出
# ROLLS回の結果を合計して回数で割る
diceA_faces_mean = sum(diceA_faces) / ROLLS
diceB_faces_mean = sum(diceB_faces) / ROLLS
print('{}を{}回振った結果の平均値は{}でした'.format(DICE_A, ROLLS, diceA_faces_mean))
print('{}を{}回振った結果の平均値は{}でした'.format(DICE_B, ROLLS, diceB_faces_mean))実行して次のような結果が出力されればOKです。
サイコロAを10回振った結果の平均値は3.8でした
サイコロBを10回振った結果の平均値は2.9でしたポイント
平均値とサイコロを振った回数の関係
もしもサイコロを6回振ってそれぞれの目が1回ずつ出たとすると、その平均値は3.5となります。
data = [1, 2, 3, 4, 5, 6]
data_summary = sum(data)
data_length = len(data)
data_mean = data_summary / data_length
print('配列の要素の合計値:' + str(data_summary))
print('配列の要素数(長さ):' + str(data_length))
print('配列の要素の平均値:' + str(data_mean))
# 出力結果
配列の要素の合計値:21
配列の要素数(長さ):6
配列の要素の平均値:3.5重さに偏りのない正6面体のサイコロは、各目が出る確率は均等であるはずですので、振った回数が増えれば増えるほど3.5に近付いて行きます。逆に、回数が少ない場合には平均値は3.5から離れる場合が増えて行きます。
平均値は算出対象とするデータの数が少ないと、実態を表せていない恐れがあるということを、よく覚えておきましょう。
4. 中央値
次は中央値を算出してみます。中央値とは、値を大きさの順番で並べた際に真ん中に位置する値のことです。まずはそのための並び替え(ソート)を行いましょう。
| (1) | 下記のコードを新しいセルに入力して、 「ランタイム」 > 「すべてのセルを実行」してください。 |
# サイコロをROLLS回振った結果の中央値を算出
# まずROLLS回の結果を目が小さい順に並び替える
diceA_faces = sorted(diceA_faces)
diceB_faces = sorted(diceB_faces)
print('{}を{}回振った結果をソートすると{}です'.format(DICE_A, ROLLS, diceA_faces))
print('{}を{}回振った結果をソートすると{}です'.format(DICE_B, ROLLS, diceB_faces))実行して次のような結果が出力されればOKです。
サイコロAを10回振った結果をソートすると[2, 2, 2, 3, 3, 3, 5, 6, 6, 6]です
サイコロBを10回振った結果をソートすると[1, 1, 1, 2, 2, 3, 4, 5, 5, 5]ですここから、真ん中の値を取り出します。偶数の場合には真ん中がありませんので、前後の値の平均値を中央値とします。
| (1) | 下記のコードを新しいセルに入力して、 「ランタイム」 > 「すべてのセルを実行」してください。 |
# 偶数個だと中央の値が2つ(10個ならば4番目と5番目)になるため、その2つの平均値を算出
# 「%」で割り算すると、あまり部分のみが取り出せる
# 「//」で割り算すると、整数部分のみがint型で取り出せる
if ROLLS % 2 == 0:
diceA_faces_median = (diceA_faces[(ROLLS // 2) - 1] + diceA_faces[(ROLLS // 2)]) / 2
diceB_faces_median = (diceB_faces[(ROLLS // 2) - 1] + diceB_faces[(ROLLS // 2)]) / 2
else:
diceA_faces_median = diceA_faces[ROLLS // 2]
diceB_faces_median = diceB_faces[ROLLS // 2]
print('{}を{}回振った結果の中央値は{}でした'.format(DICE_A, ROLLS, diceA_faces_median))
print('{}を{}回振った結果の中央値は{}でした'.format(DICE_B, ROLLS, diceB_faces_median))実行して次のような結果が出力されればOKです。
サイコロAを10回振った結果の中央値は3.0でした
サイコロBを10回振った結果の中央値は2.5でしたポイント
if文
step03.ipynb - セル 6 の 4 行目から 9 行目はif文という構文です。キーワードifから「:(コロン)」までの間に書かれた条件式が正しければ5-6行目を実行し、正しくなければ8-9行目を実行します。
ここでは、ROLLSの値が奇数か偶数かによって、処理を振り分けるためにif文を使用しています。
配列からの要素の取り出しと添字
配列の要素を取り出す場合には、diceA_faces[0]のようにして、配列の変数名に「[](角括弧)」をつけて、その中に0から始まる整数で順番を指定します。この順番のことを添字(そえじ)と言います。英語では一般的にindexと表記します。
割り算の結果
割り算では割り切れない場合に小数点以下が発生します。そのため、Pythonを含む多くの言語では、割り算の結果がint型ではなく少数を管理できる別の型(floatなど)になります。
今回のコードでは、要素数を2で割った数を添字に指定しようとしていますが、配列の添字はint型にする必要があるため、Pythonで割り算を行う「/(スラッシュ)」ではなく、割り算の結果から整数部分のみをint型として取り出せる「//」を使用しています。
なお、今回は偶数奇数判定のところで「%」でも割り算をしていますが、これは割り算のあまり部分のみを取り出す方法です。
平均値と中央値
サイコロのように確率が均等で、各要素間の差が均等(サイコロの目は1から6で1刻みに増える)であるような場合には平均値は有効です。また、十分なデータ数があれば、中央値と平均値はほぼ同じ値を示します。
しかし例えば「平均的な給与額」を出す場合を考えてみましょう。10人のうち9人が500万円で、1人だけ10億円をもらっている人がいた場合、平均値は1億450万円になってしまいます!このような場合には中央値を採用することで「平均的な給与額は500万円」という妥当な結論に辿り着けます。
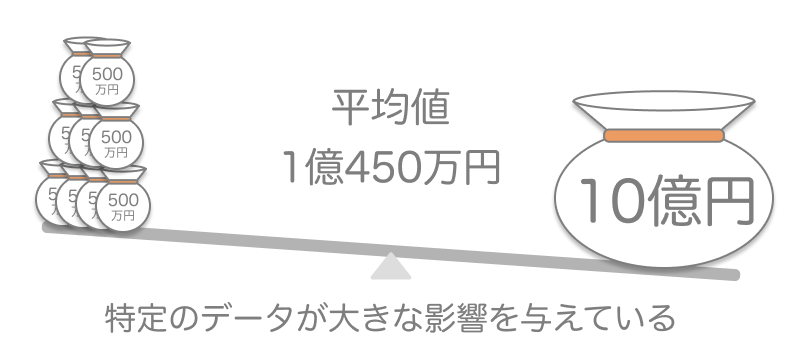

・・・それでいいのか?と感じたあなたは正しいです。10億円の人を無視する(結果的に)かどうかは、目的によります。機械学習とそれに基づく予測の分野では、このような大きく外れた値を除外することで予測の精度を高める手法が効果的な場合が多いです。
適切なデータ加工や計算手法などを選択できるようするためには、常にデータの全体を把握する必要があるということを覚えておきましょう。
5. 最頻値
最後に最頻値を算出してみます。最頻値とは、値の中で最も多く出現した値のことで、単純に値の数を数えれば良いのですが、ちょっとだけ面倒です。
まずはそれぞれの目が何回ずつ出たかを連想配列という仕組みを使って集計します。
| (1) | 下記のコードを新しいセルに入力して、 「ランタイム」 > 「すべてのセルを実行」してください。 |
# サイコロをROLLS回振った結果の最頻値を算出
# まずは目と出現回数を連想配列で集計
diceA_faces_counts = {face:diceA_faces.count(face) for face in range(1, DICE_A_MAX+1)}
diceB_faces_counts = {face:diceB_faces.count(face) for face in range(1, DICE_B_MAX+1)}
print('{}を{}回振った結果の集計結果は{}でした'.format(DICE_A, ROLLS, diceA_faces_counts))
print('{}を{}回振った結果の集計結果は{}でした'.format(DICE_B, ROLLS, diceB_faces_counts))実行して次のような結果が出力されればOKです。
サイコロAを10回振った結果の集計結果は{1: 3, 2: 1, 3: 1, 4: 3, 5: 1, 6: 1}でした
サイコロBを10回振った結果の集計結果は{1: 0, 2: 1, 3: 4, 4: 3, 5: 2, 6: 0}でした上記の出力結果をカンマ(,)で区切ってみると、コロン(:)の左側がサイコロの目、右側が出現回数になっています。この右側の出現回数が最多の項目を特定したいのですが、これは複数になる可能性がありますね。
| (1) | 下記のコードを新しいセルに入力して、 「ランタイム」 > 「すべてのセルを実行」してください。 |
# 集計結果をループ処理して出現回数が最多の目を抽出
diceA_faces_counts_max = 0
diceA_faces_mode = []
for face in diceA_faces_counts:
if diceA_faces_counts_max < diceA_faces_counts[face]:
diceA_faces_counts_max = diceA_faces_counts[face]
diceA_faces_mode = [face]
elif diceA_faces_counts_max == diceA_faces_counts[face]:
diceA_faces_mode.append(face)
print('{}を{}回振った結果の最頻値は{}で{}回でした'.format(DICE_A, ROLLS, diceA_faces_mode, diceA_faces_counts_max))
diceB_faces_counts_max = 0
diceB_faces_mode = []
for face in diceB_faces_counts:
if diceB_faces_counts_max < diceB_faces_counts[face]:
diceB_faces_counts_max = diceB_faces_counts[face]
diceB_faces_mode = [face]
elif diceB_faces_counts_max == diceB_faces_counts[face]:
diceB_faces_mode.append(face)
print('{}を{}回振った結果の最頻値は{}で{}回でした'.format(DICE_B, ROLLS, diceB_faces_mode, diceB_faces_counts_max))実行して次のような結果が出力されればOKです。
サイコロAを10回振った結果の最頻値は[1, 4]で3回でした
サイコロBを10回振った結果の最頻値は[3]で4回でしたポイント
関数の引数の個数
これまでrange関数は「0から、引数として渡した整数のひとつ手前までの整数を配列として返す」と説明してきましたが、引数が2つある場合には開始値がひとつ目の引数の値に変わります。
このように関数には引数が異なるタイプが存在する場合があります。組み込み関数については、次のページで調べられますので、見てみてください。
https://docs.python.org/ja/3/library/functions.html
連想配列
配列は0から始まる整数を添字として値を取り出せましたね。つまり、同じ型の箱にデータが順番に入れられていて「4番目の箱の中身が欲しい」というようなイメージです。
例えば、Aさんは95点、Bさんは83点・・・などのように、同じ型のデータでも、番号ではなく名前に紐付けてデータを保存/取得したい場合があります。今回の「サイコロの目と出現回数」も同じことが言えますね。このような場合に連想配列を使用します。
配列は「[](角括弧)」でしたが、連想配列は「{}(波括弧)」で括ります。そして、名前と値を「:(コロン)」で繋いで、それをセットとして管理します。
hashes = {'Aさん':95,'Bさん':83}
hashes['Cさん']=99
print('Aさんの得点は{}点でした。'.format(hashes['Aさん']))
print('Bさんの得点は{}点でした。'.format(hashes['Bさん']))
print('Cさんの得点は{}点でした。'.format(hashes['Cさん']))
# 出力結果
Aさんの得点は95点でした。
Bさんの得点は83点でした。
Cさんの得点は99点でした。値を代入する時も、取得するときも、添字に文字列型を使用することができています。
なお、連想配列もリスト内包表記で作成できることを覚えておきましょう。
平均値と中央値と最頻値
平均値や中央値と比べ、最頻値は取り扱いに注意が必要です。平均値は必ず全体を元に算出しますし、中央値はデータをソートしているため他の値との関連性は高いと言えます。しかし最頻値はその値がいちばん多かっただけであり、全体の傾向などはわかりません。もしかしたら離れたところに2番目に多い値がたくさんあって、そこがデータ群の中心地かもしれません。
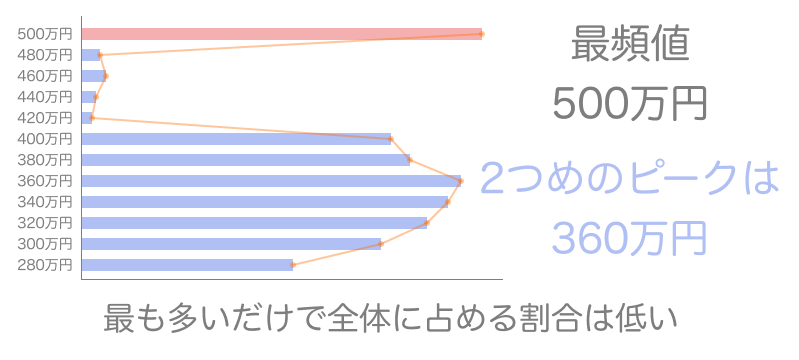
最頻値をグラフの山の頂上と捉えないように注意しましょう。
問題
確認問題
確認問題1
この中でリスト内包表記を使用したコードに対応する出力結果が正しくない組み合わせはどれか?
確認問題2
この中で次の対象配列に対する平均値・中央値・最頻値の正しい組み合わせはどれか?
data = [4, 2, 4, 2, 4, 4, 1, 2, 2, 3]実践問題
問題
step03.ipynbの各セルに必要なコードを入力して、最大値が12であるサイコロCを追加して、サイコロを20回振った結果を出力させてください。
