環境構築と実行
- 解説
- 1. Colabの実行環境を作成しましょう
- 2. 見出しを取得して出力しましょう
- 3. 表の一覧を取得して出力しましょう
解説
1. Colabの実行環境を作成しましょう
初めにプロジェクトのファイルを作成しましょう。
手順
| (1) | 「はじめに」の実行環境で控えておいたColabのURLから「python_scraping」を開いて下さい。 |
| (2) | 画面左側上部の「ファイル」タブから、「ドライブにコピーを保存」をクリックして下さい。 |
| (3) | コピーしたファイルの「python_scrapingのコピー」と書いてある箇所を「earthquake_scraping」と名前を変更して下さい。 |
| (4) | 下記説明の通り目次の「Seleniumを使うためのコマンド」を実行して下さい。 |
次に本カリキュラムではPythonのライブラリのSeleniumを使ってスクレイピングをしていきます。
Colab上でSeleniumを使うには下記コマンドを実行する必要があります。
事前に「Seleniumを使うためのコマンド」という目次があるので、実行して下さい。
実行ボタンはコードの左側の再生ボタンです。
Seleniumのインストールは少し時間がかかります、インストールが正しく終了すると出力の最後に「Successfully installed...」と表示されます。
※ランタイムの接続が切れた場合は再度実行してSeleniumをインストールして下さい。
%%shell
# Ubuntu no longer distributes chromium-browser outside of snap
#
# Proposed solution: https://askubuntu.com/questions/1204571/how-to-install-chromium-without-snap
# Add debian buster
cat > /etc/apt/sources.list.d/debian.list <<'EOF'
deb [arch=amd64 signed-by=/usr/share/keyrings/debian-buster.gpg] http://deb.debian.org/debian buster main
deb [arch=amd64 signed-by=/usr/share/keyrings/debian-buster-updates.gpg] http://deb.debian.org/debian buster-updates main
deb [arch=amd64 signed-by=/usr/share/keyrings/debian-security-buster.gpg] http://deb.debian.org/debian-security buster/updates main
EOF
# Add keys
apt-key adv --keyserver keyserver.ubuntu.com --recv-keys DCC9EFBF77E11517
apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 648ACFD622F3D138
apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 112695A0E562B32A
apt-key export 77E11517 | gpg --dearmour -o /usr/share/keyrings/debian-buster.gpg
apt-key export 22F3D138 | gpg --dearmour -o /usr/share/keyrings/debian-buster-updates.gpg
apt-key export E562B32A | gpg --dearmour -o /usr/share/keyrings/debian-security-buster.gpg
# Prefer debian repo for chromium* packages only
# Note the double-blank lines between entries
cat > /etc/apt/preferences.d/chromium.pref << 'EOF'
Package: *
Pin: release a=eoan
Pin-Priority: 500
Package: *
Pin: origin "deb.debian.org"
Pin-Priority: 300
Package: chromium*
Pin: origin "deb.debian.org"
Pin-Priority: 700
EOF
# Install chromium and chromium-driver
apt-get update
apt-get install chromium chromium-driver
# Install selenium
pip install selenium2. 見出しを取得して出力しましょう
それでは早速スクレイピングを実行していきましょう。
気象庁の地震情報サイト(以後地震情報サイト)では表示されているテキストがJavascriptによって表示されています。下記URLがサイトになりますのでアクセスしてみましょう。
https://www.data.jma.go.jp/multi/quake/index.html?lang=jp
Pythonでスクレイピングする際は色々なライブラリを使用することができます。
Javascriptによってテキストを表示させるサイトについてはSeleniumを使ってスクレイピングしていきます。
スクレイピングではHTMLの要素を確認する必要があります。
確認する際はサイト上で右クリックから「検証」を選択しデベロッパーモードを表示して、上部の「Elements(要素)」を選択して下さい。
選択するとHTML構造を確認することができます。
下記手順に従って実行していきましょう。
※目次の「Google スプレッドシートの認証を許可するためのコマンド」はスプレッドシートに書き込む際に必要なので今は実行しなくて大丈夫です。
手順
| (1) | 目次の「import」のセルコードに下記コードを貼り付けて実行して下さい。 |
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium import webdriver
import time
# オプション追加
options = Options()
options.add_argument('--headless')
options.add_argument('-no-sandbox')| (2) | 目次の「関数」のセルコードに下記コードを貼り付けて実行して下さい。 |
# WebDriverインスタンスを作成
def create_driver(url):
driver = webdriver.Chrome(options=options)
driver.get(url)
return driver| (3) | 目次の「実行環境」のセルコードに下記コードを貼り付けて実行して下さい。 ※セルコードを追加する場合は「+コード」で追加できます。 |
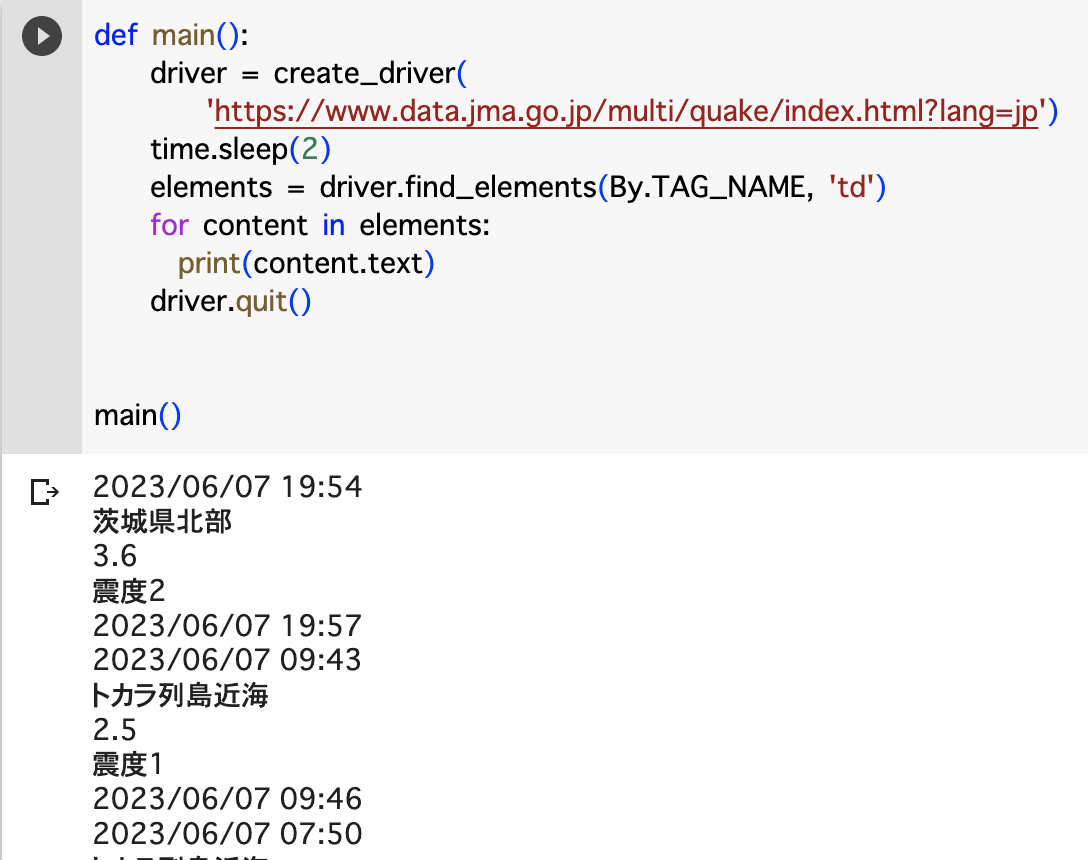
# 実行する関数
def main():
driver = create_driver(
'https://www.data.jma.go.jp/multi/quake/index.html?lang=jp')
time.sleep(2)
element = driver.find_element(By.ID, 'header')
print(element.text)
driver.quit()
main()解説
options = Options()
options.add_argument('--headless')
options.add_argument('--no-sandbox')これで必要なオプションを追加します。
「--headless」はヘッドレスモードと言い、通常Seleniumは実際のブラウザが表示されますが、このオプションを追加することによってブラウザが表示されなくなります。さらサーバーにかかる負荷も軽減しますのでブラウザを表示させる必要の無い場合は追加しましょう。
「--no-sandbox」オプションは、Chromeブラウザをセキュリティサンドボックスモードで起動しないことを指定します。SeleniumをColabで使用する際にセキュリティ制約を緩和し、必要な操作やタスクを実行することができます。
ただし、注意点として、「--no-sandbox」を使用することは、セキュリティリスクを伴う場合があります。Colab環境でのSeleniumの使用は、注意深く、信頼できるソースからのコードのみを実行するようにしてください。
def create_driver(url):
driver = webdriver.Chrome(options=options)
driver.get(url)
return driverdriver = create_driver(
'https://www.data.jma.go.jp/multi/quake/index.html?lang=jp')
time.sleep(2)「create_driver」の中ではChromeの「WebDriverインスタンス」を作成します。optionsを指定することで、先程のオプションが適用されたChromeブラウザが起動します。
「get」関数を使用して指定されたURLにアクセスします。WebDriverインスタンスであるdriverを使用して、ブラウザが指定したURLをロードします。
地震情報サイトでは表示されているテキストはJavascriptによって表示されていますので、
「time.sleep(2)」によって2秒待機し描画されるのを待ちましょう。
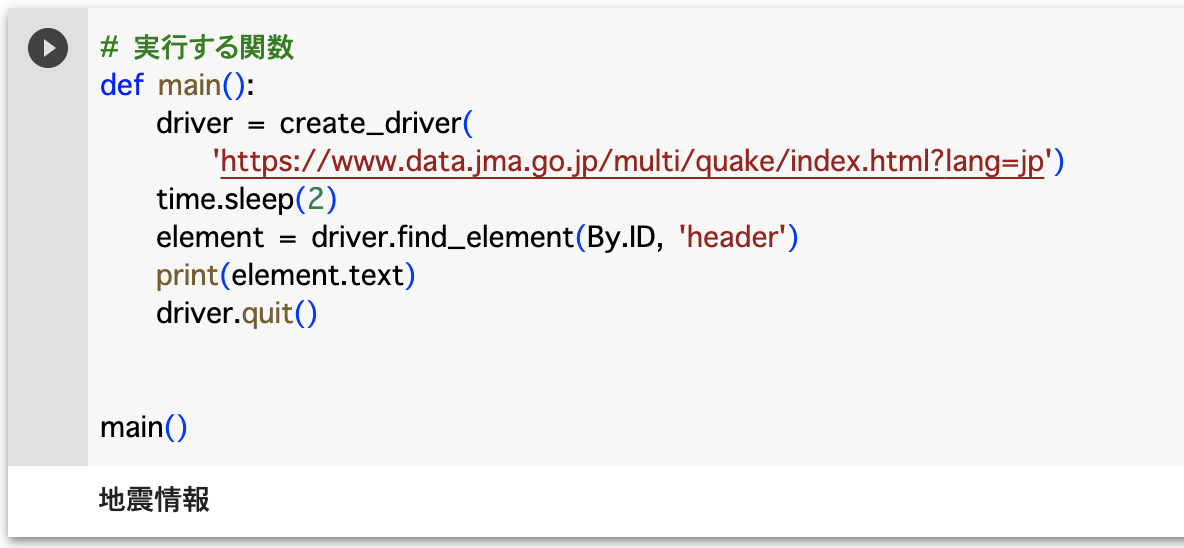
element = driver.find_element(By.ID, 'header')
print(element.text)
driver.quit()「find_element(By.ID, 'header')」ではHTML内に存在する、idが「header」のHTML要素を取得します。
「element.text」は取得した要素のテキストのみ表示させることができます。
「create_driver」によって生成した「WebDriver」は処理の最後に必ず「driver.quit()」で正く終了して下さい。
これでコードを実行すると「地震情報」と出力されます。
3. 表の一覧を取得して出力しましょう
次は表の一覧を取得して出力しましょう。
地震情報サイトの表はHTMLの「table」タグで表示されています。
tableタグは「tr」「th」「td」タグで構成されています。
trタグは行を表します。trタグ内にはthまたはtdを配置します。
thタグはテーブルのヘッダーセルを表します。通常、テーブルの最初の行に配置されます。
tdタグはテーブルのデータセルを表します。ヘッダーセル以降の行に配置されます。
地震情報サイトの「table」タグのHTML構造がどうなっているのかデベロッパーモードで確認して見ましょう。
表の一覧を取得するコードは下記になります。
手順
| (1) | 目次の「実行環境」で「+コード」を押してセルコードを追加して下さい。 |
| (2) | 追加したセルコードに下記コードを貼り付けて実行して下さい。 |
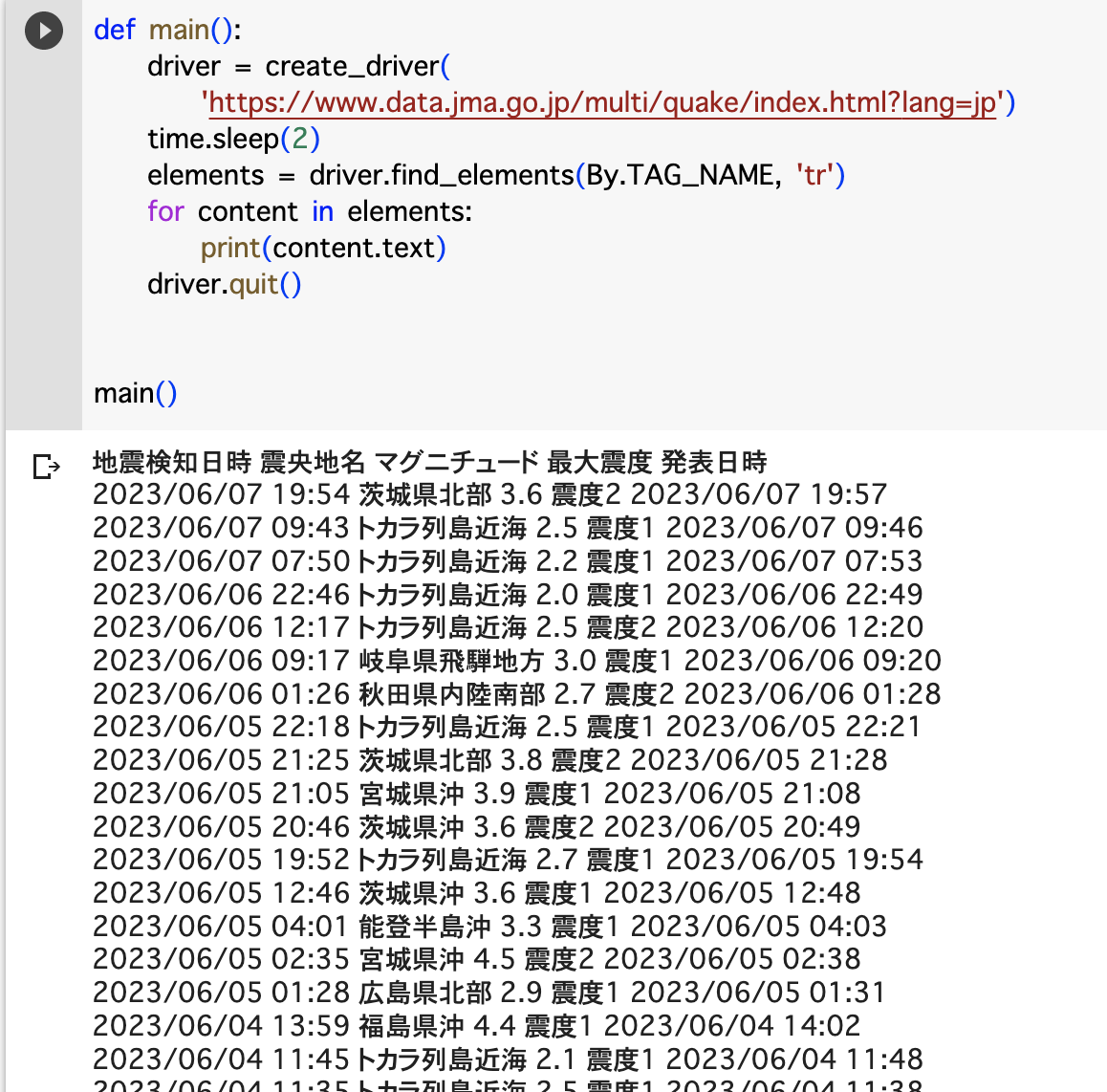
def main():
driver = create_driver(
'https://www.data.jma.go.jp/multi/quake/index.html?lang=jp')
time.sleep(2)
elements = driver.find_elements(By.TAG_NAME, 'tr')
for content in elements:
print(content.text)
driver.quit()
main()解説
elements = driver.find_elements(By.TAG_NAME, 'tr')見出しを取得する時と同じような構文ですがこちらは指定したタグの名前を複数取得することができます。
これでサイト内にある「tr」タグを複数取得しリストにして代入しています。
for content in elements:
print(content.text)取得した「tr」タグのリストをfor文を使ってループ処理し1行ずつ出力しています。
実行すると地震情報の表の一覧情報が出力されます。
問題
確認問題
確認問題
この中で「Selenium」実行時ブラウザを表示させないようにする際に正しいものはどれか?
実践問題
各問に答えてください。
※セルコードを追加して新たにコードを書いてもカリキュラム内で実行した関数を変更しても構いません。
| (1) | 地震情報サイトでデベロッパーモードを表示してh2タグのidを確認し、テキストを表示させて下さい。 |
| (2) | 「td」タグのテキストを1セルずつ出力して下さい。 |
解答
element = driver.find_element(By.ID, 'sub_header')
print(element.text)想定結果
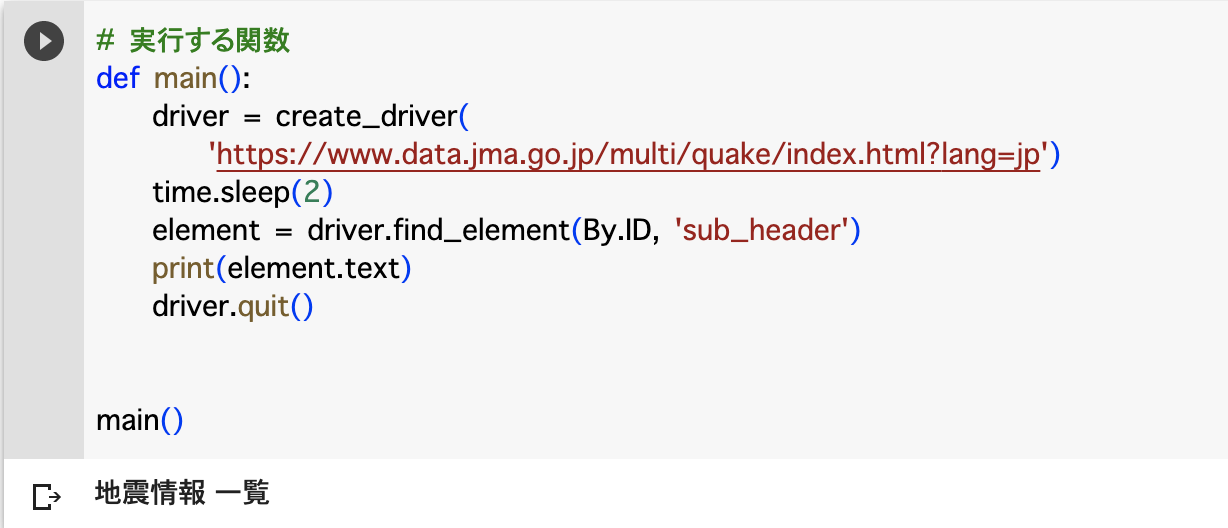
elements = driver.find_elements(By.TAG_NAME, 'td')
for content in elements:
print(content.text)想定結果