フィルター
- 解説
- 1. filter機能を実装しましょう
解説
1. filter機能を実装しましょう
次は任意の値でfilterをかけて値を取得し出力しましょう。
今回は「マグニチュード」と「最大震度」どちらかの基準の値を自分で設定し、その値よりも大きい行を取得します。
手順
| (1) | 目次の「関数」のセルコードに下記コードを追加し、実行して下さい。 |
# 指定したタグを見つけてリストを返す
def get_elements(elements, tag_name):
return elements.find_elements(By.TAG_NAME, tag_name)
# fieldから条件に使う数値を取得
def create_condition_number(selected_field, filter_field):
return float(selected_field) if filter_field == 'マグニチュード' else int(
selected_field[2]) if selected_field != '-' else 0| (2) | 目次の「実行環境」で「+コード」を押してセルコードを追加して下さい。 |
| (3) | 追加したセルコードに下記コードを追加し、実行して下さい。 |
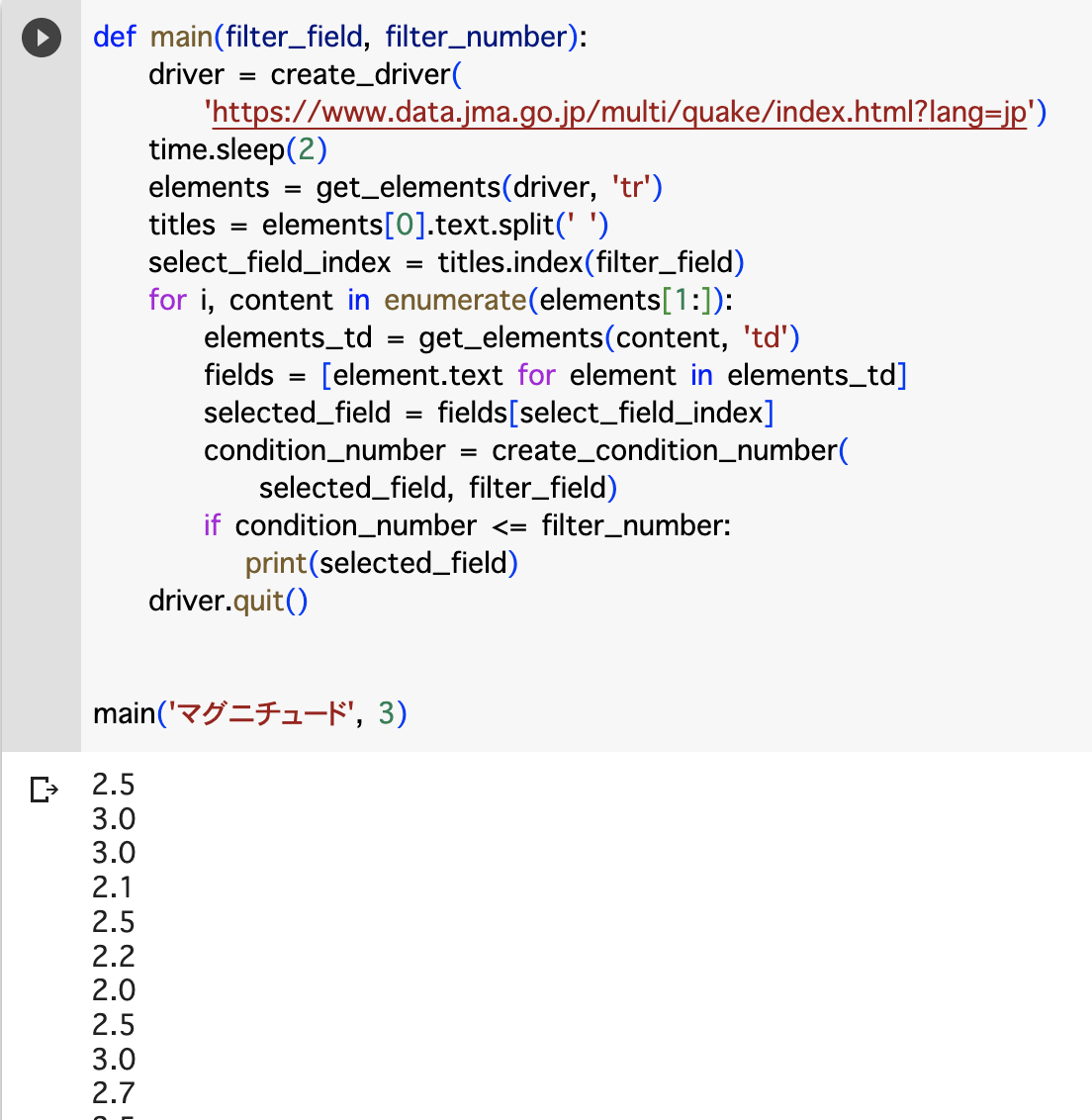
def main(filter_field, filter_number):
driver = create_driver(
'https://www.data.jma.go.jp/multi/quake/index.html?lang=jp')
time.sleep(2)
elements = get_elements(driver, 'tr')
titles = elements[0].text.split(' ')
select_field_index = titles.index(filter_field)
for i, content in enumerate(elements[1:]):
elements_td = get_elements(content, 'td')
fields = [element.text for element in elements_td]
selected_field = fields[select_field_index]
condition_number = create_condition_number(
selected_field, filter_field)
if condition_number >= filter_number:
print(selected_field)
driver.quit()
main('マグニチュード', 5)
解説
def main(filter_field, filter_number):
driver = create_driver(
'https://www.data.jma.go.jp/multi/quake/index.html?lang=jp')
main('マグニチュード', 5)任意のフィールドと値を渡すために「引数」を設定します。
今回はfilterをかけるfieldを「filter_field」、基準の値を「filter_number」とします。
def get_elements(elements, tag_name):
return elements.find_elements(By.TAG_NAME, tag_name)
elements = get_elements(driver, 'tr')「get_elements」関数では前回までやったようにHTMLの中から指定したタグを見つけてリストを返す関数です。
第1引数に「WebDriver」または「WebElements」、第2引数に取得したいタグを指定します。
titles = elements[0].text.split(' ')
select_field_index = titles.index(filter_field)最初の行はfileldの見出しの行なので、取得したリストの最初の要素のテキストを空白刻みのリストにしています。

次に引数に渡した任意のfilter_fileldがこのリストの何番目にあるのか調べてそのindex番号を「select_field_index」に代入しています。
この番号を使って取得したいfieldの値を指定することができます。
for i, content in enumerate(elements[1:]):「enumerate」関数は反復可能なオブジェクトを受け取り、各要素とそのインデックスを生成します。
elementsの中の最初の行はfieldの見出しなので最初の行は飛ばして実行します。
「elements[1:]」はelementsリストの2番目の要素から最後の要素までの部分リストを作成します。
この部分リストがループの対象となります。
これで2番目の要素からfor文が開始されます。
elements_td = get_elements(content, 'td')
fields = [element.text for element in elements_td]
selected_field = fields[select_field_index]各要素の中からさらに「td」タグを取得し、そのテキストのリストを「fields」に代入します。
そして先程取得した「select_field_index」を使ってfilterをかけるfieldを指定します。
今回の場合selected_fieldにはマグニチュードの値が入っています。
def create_condition_number(selected_field, filter_field):
return float(selected_field) if filter_field == 'マグニチュード' else int(
selected_field[2]) if selected_field != '-' else 0condition_number = create_condition_number(
selected_field, filter_field)「create_condition_number」では該当したfieldから条件に使う数値を取得します。
この三項演算子はもし「filter_field」がマグニチュードだったならばマグニチュードの値を返し、最大震度でかつ「-」でなければ震度の値を、「-」であれば「0」を返す関数です。
マグニチュードは小数点の文字列型なので「selected_field」に「float()」関数で「浮動小数点数型」に型変換して返します。
最大震度は「震度【数値】」または「-」の文字列となっています。
「-」でなければ「selected_field」の3文字目の【数値】を「int()」関数で「整数型」に型変換して返し、「-」であれば上記の通り数字の「0」を返します。
※小数点の文字列に「int()」関数で整数型に型変換しようとするとエラーになります。
if condition_number >= filter_number:
print(selected_field)最後に先程取得した値がfilter_number以上のfieldのみの条件分岐で出力します。
今回の場合だと実行するとマグニチュードが5以上の値が出力されます。
※地震情報サイトはリアルタイムに更新するのでプログラムを実行した時にマグニチュードが5以上のものが無い場合があります。その際は値を変えて実行して下さい。
問題
確認問題
確認問題
この中で整数型の使い方として正しくないものはどれか?
実践問題
各問に答えて下さい。
※セルコードを追加して新たにコードを書いてもカリキュラム内で実行した関数を変更しても構いません。
| (1) | 最大震度が3以上の値を出力して下さい。 |
| (2) | マグニチュードが3以下の値を出力して下さい。 |
解答
main('最大震度', 3)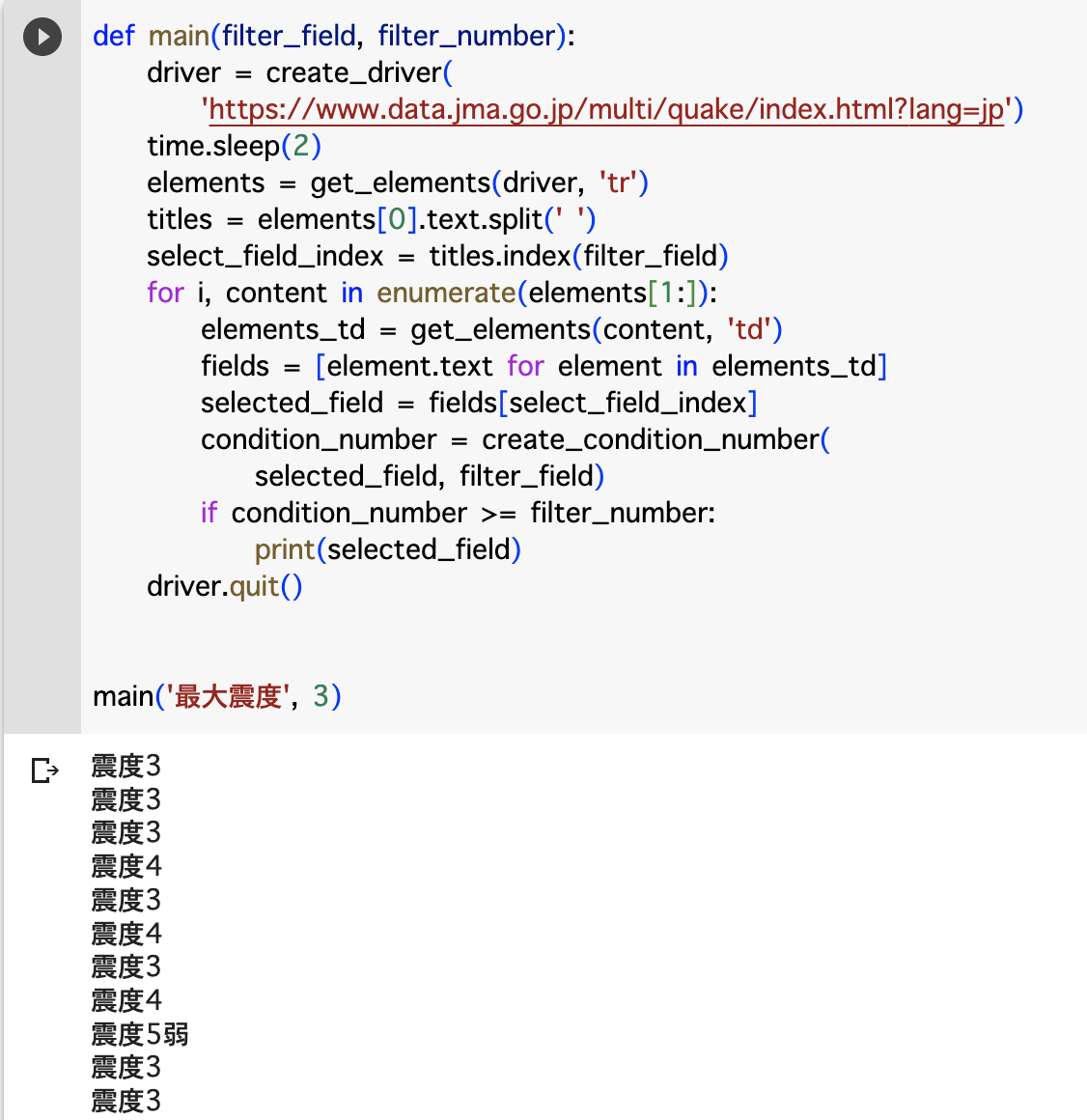
if condition_number <= filter_number:
print(selected_field)
# -----------------------------------
main('マグニチュード', 3)