ファイル書き込み
- 解説
- 1. テキストファイルに書き込みましょう
- 2. Google スプレッドシートに書き込みましょう
解説
1. テキストファイルに書き込みましょう
次は取得した表をテキストファイルに書き込みましょう。
先に「earthquake_info」というフォルダを作成しておきます。
Colabの左側のファイルを選択後、右クリックをして「新しいフォルダ」から作成して下さい。
手順
| (1) | 目次の「関数」のセルコードに下記コードを追加し、実行して下さい。 |
slash = ' / '
# 空白スラッシュ刻みの文字列を作成
def create_text(data):
text = data[0] + slash + data[1] + slash + data[2] + \
slash + data[3] + slash + data[4] + slash + \
data[5] + slash + data[6] + '\n\n'
return text| (2) | 目次の「実行環境」で「+コード」を押してセルコードを追加して下さい。 |
| (3) | 追加したセルコードに下記コードを追加し、実行して下さい。 |
def main(filter_field, filter_number, file_name):
urls = []
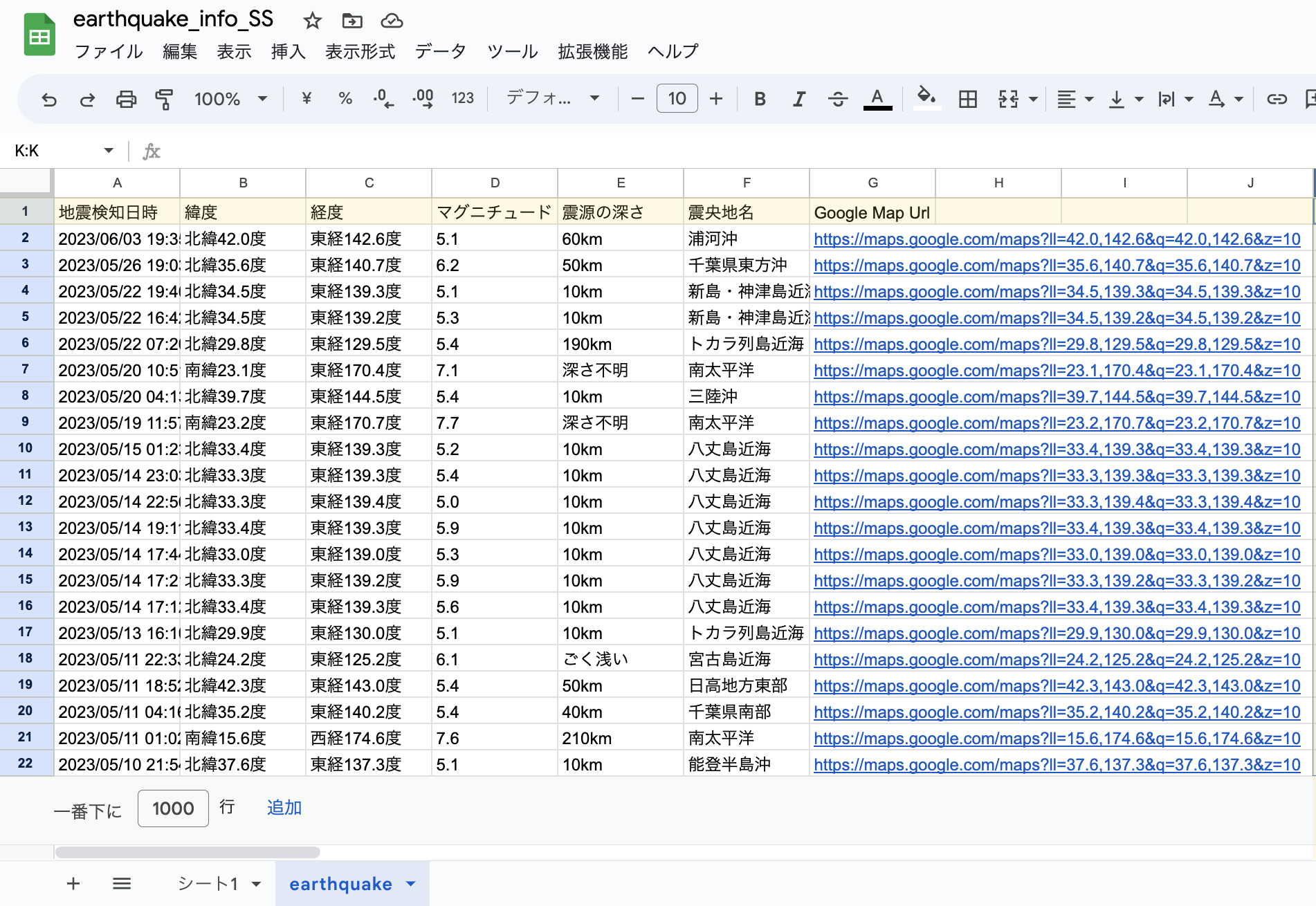
scraiping_data = [['地震検知日時', '緯度', '経度',
'マグニチュード', '震源の深さ', '震央地名', 'Google Map Url']]
driver = create_driver(
'https://www.data.jma.go.jp/multi/quake/index.html?lang=jp')
time.sleep(2)
elements = get_elements(driver, 'tr')
titles = elements[0].text.split(' ')
select_field_index = titles.index(filter_field)
for i, content in enumerate(elements[1:]):
elements_td = get_elements(content, 'td')
fields = [element.text for element in elements_td]
selected_field = fields[select_field_index]
condition_number = create_condition_number(
selected_field, filter_field)
if condition_number >= filter_number:
url = get_url(elements_td[0])
urls.append(url)
for url in urls:
driver.get(url)
time.sleep(2)
detail_elements_tr = get_elements(driver, 'tr')
detail_elements_td = get_elements(detail_elements_tr[1], 'td')
coordinate = create_coordinate(detail_elements_td)
google_map_url = 'https://maps.google.com/maps?ll=' + \
coordinate + '&q=' + coordinate + '&z=10'
detail_fields = [element.text for element in detail_elements_td]
detail_fields.append(google_map_url)
scraiping_data.append(detail_fields)
if len(scraiping_data) > 0:
file = open('earthquake_info/' + file_name + '.txt', 'a')
for data_to_write in scraiping_data:
file.write(create_text(data_to_write))
file.close()
driver.quit()
main('マグニチュード', 5, 'earthquake')
解説
scraiping_data = [['地震検知日時', '緯度', '経度',
'マグニチュード', '震源の深さ', '震央地名', 'Google Map Url']]
# -------------------------------------------------------------------
detail_fields = [element.text for element in detail_elements_td]
detail_fields.append(google_map_url)
scraiping_data.append(detail_fields)行のテキストのリストを作成し、そこに前回取得したGoogle MapのURLを追加しています。
この詳細ページの表のリストをファイルに書き込む用のリストに追加しています。
このリストの先頭には各見出しをあらかじめ追加しています。
if len(scraiping_data) > 0:
file = open('earthquake_info/' + file_name + '.txt', 'a')
# -----------------------------------------------------------------
main('マグニチュード', 5, 'earthquake')データを取得できなかった場合は書き込まないようにif文を追加します。
「open」関数はファイルを開いて読み書きするための組み込み関数です。
第1引数にファイルのパスを渡し、第2引数にはどのモードで開くかを指定できます。
今回はファイルがある場合は追記にしたいので第2引数に「a」を指定します。
| 'r' | 既存ファイルを読み込みモード(ない場合はエラー)で開く ※デフォルト |
| 'w' | ファイルを書き込みモード(保存時は上書き)で開く |
| 'x' | 新規ファイルを書き込みモード(既にある場合はエラー)で開く |
| 'a' | ファイルを書き込みモード(保存時は既存内容の下に追記)で開く |
main関数の第3引数にファイルを任意に変えれるようにファイル名を渡せるようにします。
slash = ' / '
def create_text(data):
text = data[0] + slash + data[1] + slash + data[2] + \
slash + data[3] + slash + data[4] + slash + \
data[5] + slash + data[6] + '\n\n'
return textfor data_to_write in scraiping_data:
file.write(create_text(data_to_write))
file.close()「create_text」関数では渡されたリストを空白スラッシュ刻みの文字列に変換して返します。
「write」関数で先程指定したファイルに1行ずつ書き込みしていきます。
書き込みが終わったらclose関数で終わらせましょう。
これで実行するとearthquake_infoフォルダ内にファイルが作られ、表のデータが書き込まれています。

2. Google スプレッドシートに書き込みましょう
最後にGoogle スプレッドシートに書き込んでいきましょう。
先に書き込むスプレッドシートを作成しておきます。手順は下記の通りです。
Google スプレッドシート作成手順
| (1) | ドライブをクリックしてGoogle ドライブに移動して下さい。 |
| (2) | 「+新規」をクリックして「Google スプレッドシート」を選択して下さい。 |
| (3) | 新規作成したブック名を「earthquake_info_SS」に変更して下さい。 |
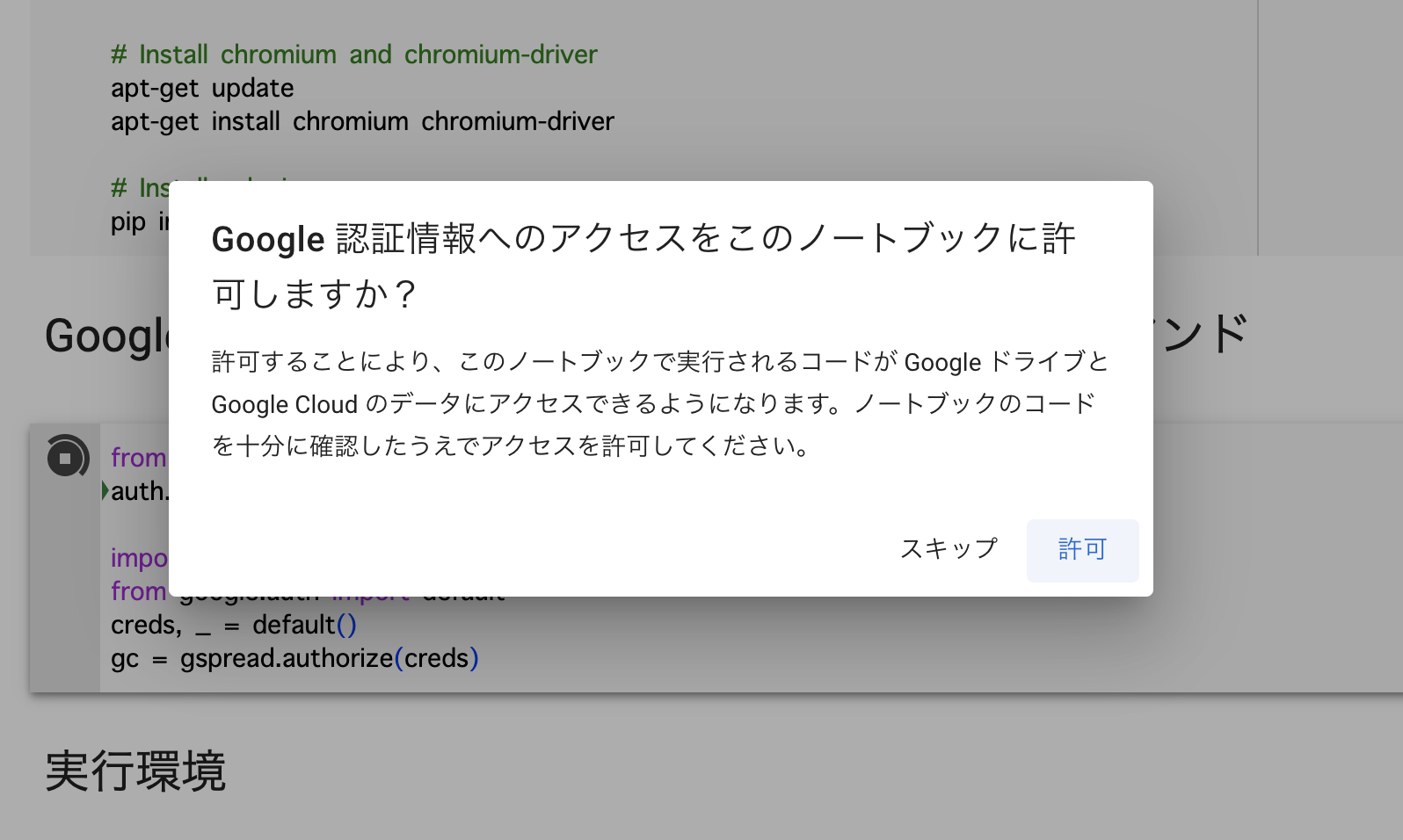
Colabでスプレッドシートにアクセスする際に認証を許可しなければなりません。
目次の「Google スプレッドシートの認証を許可するためのコマンド」からコードを実行して下さい。
from google.colab import auth
auth.authenticate_user()
import gspread
from google.auth import default
creds, _ = default()
gc = gspread.authorize(creds)これでブックを作成したgoogleアカウントを選択して認証を許可して下さい。
それではコードを実行していきましょう。
手順
| (1) | 目次の「実行環境」で「+コード」を押してセルコードを追加して下さい。 |
| (2) | 追加したセルコードに下記コードを追加し、実行して下さい。 |
def main(filter_field, filter_number, file_name):
urls = []
scraiping_data = [['地震検知日時', '緯度', '経度',
'マグニチュード', '震源の深さ', '震央地名', 'Google Map Url']]
driver = create_driver(
'https://www.data.jma.go.jp/multi/quake/index.html?lang=jp')
time.sleep(2)
elements = get_elements(driver, 'tr')
titles = elements[0].text.split(' ')
select_field_index = titles.index(filter_field)
for i, content in enumerate(elements[1:]):
elements_td = get_elements(content, 'td')
fields = [element.text for element in elements_td]
selected_field = fields[select_field_index]
condition_number = create_condition_number(
selected_field, filter_field)
if condition_number >= filter_number:
url = get_url(elements_td[0])
urls.append(url)
for url in urls:
driver.get(url)
time.sleep(2)
detail_elements_tr = get_elements(driver, 'tr')
detail_elements_td = get_elements(detail_elements_tr[1], 'td')
coordinate = create_coordinate(detail_elements_td)
google_map_url = 'https://maps.google.com/maps?ll=' + \
coordinate + '&q=' + coordinate + '&z=10'
detail_fields = [element.text for element in detail_elements_td]
detail_fields.append(google_map_url)
scraiping_data.append(detail_fields)
if len(scraiping_data) > 0:
file = open('earthquake_info/' + file_name + '.txt', 'a')
for data_to_write in scraiping_data:
file.write(create_text(data_to_write))
file.close()
book = gc.open_by_key(【key】)
sheet_titles = [sheet.title for sheet in book.worksheets()]
sheet = book.add_worksheet(file_name, rows=len(scraiping_data), cols=100) if not (
file_name in sheet_titles) else book.worksheet(file_name)
sheet.append_rows(scraiping_data)
driver.quit()
main('マグニチュード', 5, 'earthquake')解説
book = gc.open_by_key(【key】)「gc.open_by_key」関数を使ってスプレッドシートのブックにアクセスします。
引数にはブックそれぞれのkeyを文字列として渡します。このkeyはブックのURLから知ることができます。
「spreadsheets/d/【key】/edit#gid=」
URLのこの箇所がkeyになります。確認してシングルクォーテーションで囲って書き換えて下さい。
sheet_titles = [sheet.title for sheet in book.worksheets()]ブックにあるシートの名前のリストを取得しています。
同じシート名で作成しようとするとエラーになってしまいますのでその時の判定に使います。
sheet = book.add_worksheet(file_name, rows=len(scraiping_data), cols=100) if not (
file_name in sheet_titles) else book.worksheet(file_name)
sheet.append_rows(scraiping_data)この三項演算子ではもし指定されたシート名が既存のブックになければデータ数分の行のシートを作成し、もしあればそのシートを読み込むという判定をしています。
この条件式の後に「append_rows」関数でリストの中身を1つずつセルに書き込んでいきます。
これで実行するとスプレッドシートに「earthquake」というシートが追加され書き込まれます。
問題
確認問題
確認問題
この中で「test.txt」ファイルに上書きするコードで正しいものはどれか?
実践問題
各問に答えて下さい。
※セルコードを追加して新たにコードを書いてもカリキュラム内で実行した関数を変更しても構いません。
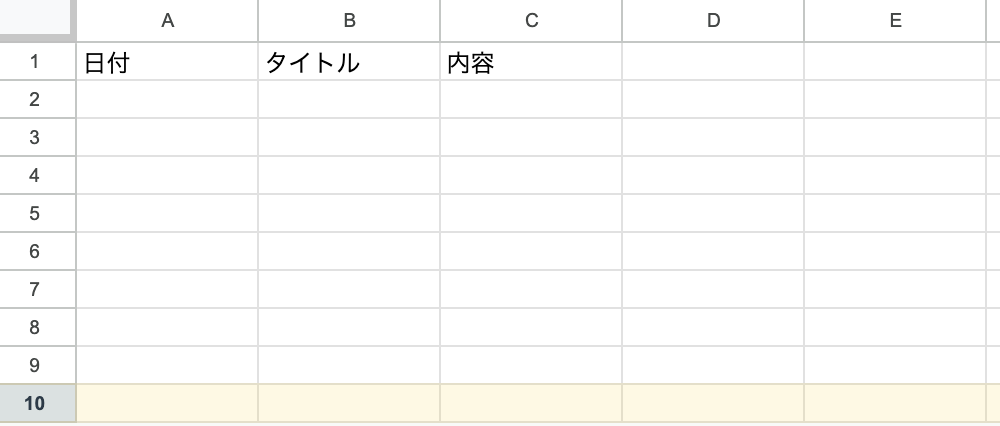
| (1) | ブックのシート名のリストを出力して下さい。 |
| (2) | スプレッドシートに10行10列の「TEST」というシートをPythonを使って作成して下さい。 |
| (3) | (2)で作成した「TEST」シートに「日付」「タイトル」「内容」と1行に1セルずつ書き込んで下さい。 |
解答
def main():
book = gc.open_by_key(【key】)
sheet_titles = [sheet.title for sheet in book.worksheets()]
print(sheet_titles)
main()
def main():
book = gc.open_by_key(【key】)
book.add_worksheet('TEST', rows=10, cols=10)
main()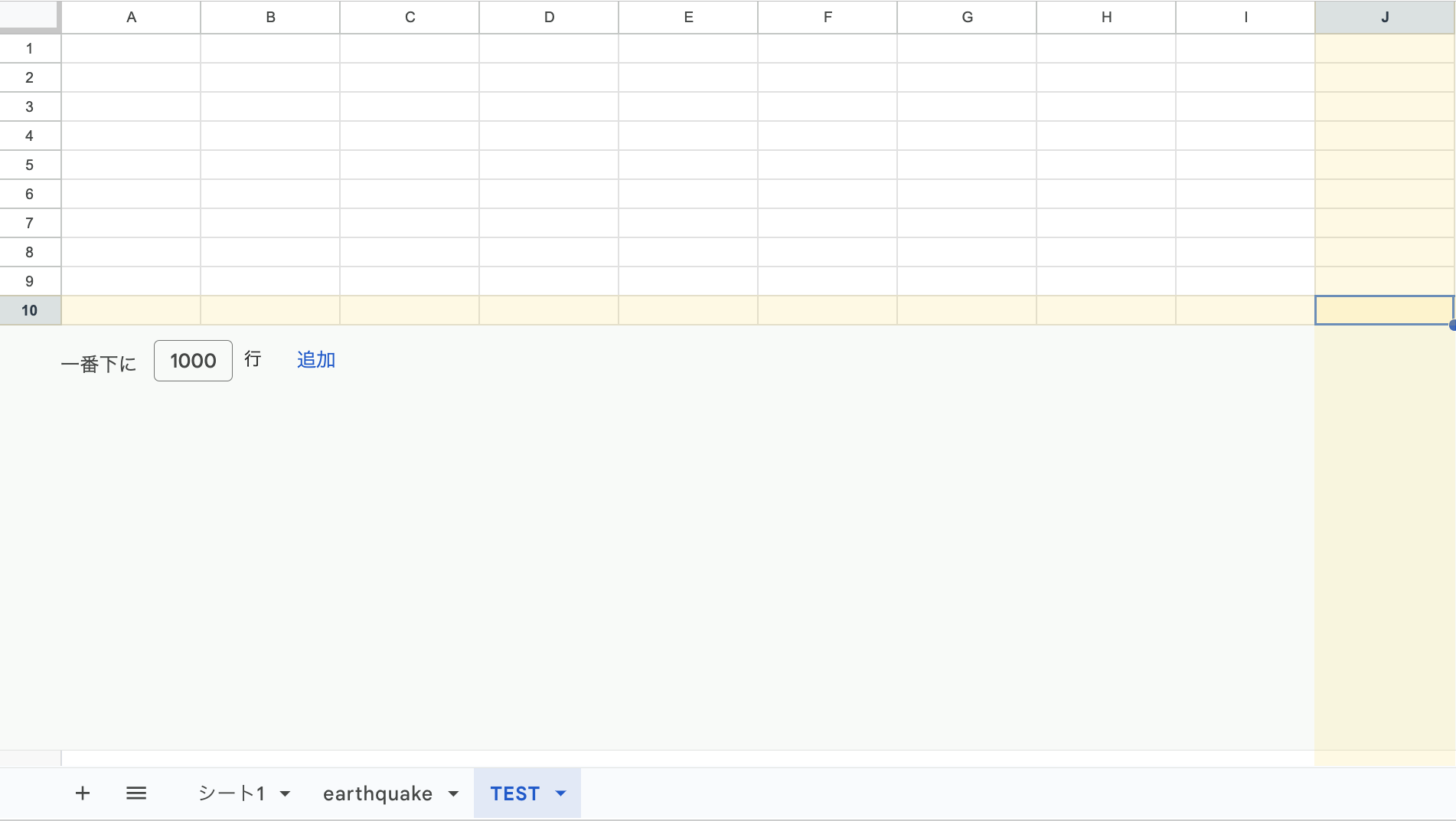
def main():
book = gc.open_by_key(【key】)
sheet = book.worksheet('TEST')
sheet.append_rows([['日付','タイトル','内容']])
main()